Note: This is the first of a multi-part series in which we will be building a fully-automated deployment system.
Objective
Set up a deployment server on CentOS 7 for Linux hosts. Target hosts may be CentOS 6 or 7.
Prerequisites
On the deployment server, have DNS (bind) and DHCP configured and running. Use kickstart for laying down the OS, and Ansible for configuration.
Environment
Here's what the build environment looks like. This will guide many of the configuration decisions below.
Deployment Server: a CentOS 7 server with the address: 172.16.1.1/16, and hostname of 'deploy'.
Provides:
Discussion
This first installment is strictly setting up the PXE environment and repositories so we can deploy a server. Manual attendance is required to select the appropriate image, perform final networking configurations, and similar tasks. In later additions, we will be automating end-to-end deployments. But, in the meantime, we don't want to redesign our environment as we go, so we're making some decisions now that may seem overkill, or otherwise not necessary. For example, all home, and application directories are made available via NFS. In this way, once the end-to-end deployment process completes, a server should be able to do a final boot, and be ready to start work.
The build philosophy is rather straight-forward. There will be multiple phases: OS Deploy, OS Configuration, Application Deploy, etc. Each phase handles only the minimum tasks required to get us to the next phase. There is one exception to this rule: In the event that a task may be completed in multiple phases, and the outcome of that task is more reliable in a later phase, we will perform that task later, rather than earlier. Simplicity is important, but reliability is non-negotiable.
Rebooting is only necessary at the end in the event that we change the status of selinux. If selinux is already disabled when you begin, a reboot is not required. Instead, I would recommend restarting each service as you complete the configuration changes for that service. This is easily enough accomplished with:
# systemctl restart <servicename>.service
where <serivicename> is httpd, dhcpd, or xinetd.
We will be performing the entirety of this installation as the root user. Consider that it is bad practice to manage a server as root, but in this case, I consider this activity to be standing up a server, rather than operational maintenance. As such, it is likely not yet in production, so the standard to which we work is different. That said, you will be root, so read and understand each command below before you type it in at the keyboard.
Configuring the client is largely left to the reader, but I will provide some hints, particularly as they apply to VirtualBox.
- It makes no difference at all whether the disk is dynamic, or fully allocated when the VM is created. What does make a difference (at least for the procedure below) is that the disk is at least 8Gb is size. The disk partitioning section of the KVM will need an 8 Gb disk at a miminum (larger is OK, but extra space won't get used with the kickstart file directives below).
- Make sure to set the host to boot from Hard disk first, then PXE. You can disable CD and floppy completely. (Regardless, My VirtualBox still asks to map a CD-ROM when the host first boots, but you can ignore that message by clicking the Cancel button. The deploy will continue.
- In the Network settings, set the adapter to 'Bridged'. If it's NAT, it will not be able to find the DHCP server, and the deploy will fail.
Installation
On the deployment server:
- # yum install httpd xinetd syslinux tftp-server -y
When complete, /var/lib/tftbboot/ will be the PXE directory.
Configure PXE on the deployment host
# cd /usr/share/syslinux/
Copy the following TFTP configuration files to the /var/lib/tftpboot/ directory.
# cp pxelinux.0 menu.c32 memdisk mboot.c32 chain.c32 /var/lib/tftpboot/
Edit file /etc/xinetd.d/tftp and enable TFTP server.
# vim /etc/xinetd.d/tftp
Change “yes” next to disable to “no”. Save and quit:
:wq
Set Up Repositories
It is assumed that you either have sufficient disk to house repositories (they can run from 4Gb - 7Gb each). My deployment server is a KVM virtual guest, and I have a KVM .img file sitting on the side with the repos on it. I mount it under /var/lib/tftpboot/repository/. My initial repo is CentOS 7.2 (build 1511) stored in: /var/lib/tftpboot/repository/CentOS-7-1511-x86_64/. Ideally, the goal is to provision servers such that they are alike, so we would not house too many repositories. 50Gb - 100Gb should be sufficient for most shops.
# mkdir /var/lib/tftpboot/repository/
If you are mounting a separate partition/device under /var/lib/tftpboot/repository/, do so now.
Here, we set the appropriate permissions so that hosts can access files in the repo when needed.
# cd /var/lib/tftpboot
# chown -R apache.apache *
# cd repository
# find . -type f -exec chmod -R 744 {} \;
# find . -type d -exec chmod -R 755 {} \;
Configure the Apache httpd Service
We will be using the Apache httpd web server to make files available. We need to configure permissions within Apache, as well as at the file system level.
# vim /etc/httpd/conf.d/pxeboot.conf
There are a few customizations required here. The IP network number must match the network from which clients will be booting. I've selected 172.16.0.0/16, as a that matches my setup. You will also need to specify the directory used for the repo. The settings below will make sure all hosts within your subnet have access to the repository files. If you have a limited DHCP range, you could tighten this down a little further to hosts in that DHCP range. See www.apache.com for details on setting up access.
For servers running Apache 2.2, add the following and save:
Alias /repository /var/lib/tftpboot/repository
<Directory /var/lib/tftpboot/repository>
Options Indexes FollowSymLinks
Order Deny,Allow
Deny from all
Allow from 127.0.0.1 172.16.0.0/16
</Directory>
For servers running Apache 2.4, add the following and save:
Alias "/repository" "/var/lib/tftpboot/repository"
<Directory "/var/lib/tftpboot/repository">
Options Indexes FollowSymLinks
Require ip 172.16.0.0/16
</Directory>
Validate the Apache configuration:
# apachectl configtest
If all goes well, the command should return "Syntax OK".
If selinux was already disabled, you can simply restart httpd now using the command shown above. Otherwise, the new settings will be applied at reboot time.
Configure the PXE Boot Service
# vim /var/lib/tftpboot/pxelinux.cfg/default
Add the following and save:
DEFAULT menu
PROMPT 0
MENU TITLE ----==== Host Deploy System ====----
TIMEOUT 200
TOTALTIMEOUT 6000
ONTIMEOUT local
LABEL local
MENU LABEL (local)
MENU DEFAULT
LOCALBOOT -1
LABEL CentOS-7-1511-x86_64_KVM
kernel /repository/CentOS-7-1511-x86_64/images/pxeboot/vmlinuz
MENU LABEL CentOS-7-1511-x86_64 KVM
append initrd=/repository/CentOS-7-1511-x86_64/images/pxeboot/initrd.img lang= rd_NO_LVM rd_NO_MD rd_NO_DM
inst.ks=http://172.16.1.1/repository/templates/CentOS7-1511-KVM_base.cfg
inst.repo=http://172.16.1.1/repository/CentOS-7-1511-x86_64
ipappend 2
LABEL CentOS-7-1511-x86_64_OVB
kernel /repository/CentOS-7-1511-x86_64/images/pxeboot/vmlinuz
MENU LABEL CentOS-7-1511-x86_64 Oracle VirtualBox
append initrd=/repository/CentOS-7-1511-x86_64/images/pxeboot/initrd.img lang= rd_NO_LVM rd_NO_MD rd_NO_DM
inst.ks=http://172.16.1.1/repository/templates/CentOS7-1511-OVB_core.cfg
inst.repo=http://172.16.1.1/repository/CentOS-7-1511-x86_64
ipappend 2
MENU end
This probably requires a little discussion, as there is a lot going on in this configuration file. /var/lib/tftpboot/pxelinux.cfg/default is the default file that is sent to a server requesting PXE boot services. Other than default, you can specify a configuration file for an individual host (the host's MAC address is the filename), or configuration files for sets of MAC addresses. We're not there yet, so for now, we're going to set up just the default, and build upon that later.
We have two menu items, one for a KVM guest, and one for an Oracle VirtualBox guest (yes, for the moment, we are only deploying virtual machines). This is because the details of the kickstart files vary significantly from one to the other, and this is a clean way to specify how each should be build. Once we move on to push-button installs, the multiple menu items will be of little use.
There are some specific settings in the 'append' line that deserve mention:
- rd_NO_LVM: We're not using LVM, but we could do so easily. What's important is that if the kickstart file we use builds storage using LVM, this parameter must be removed from the append line.
- rm_NO_MD: Same here; no software RAID is being used, so we remove that from the build OS environment.
- rd_NO_LUKS: We're not encrypting any disks, so no need to load support for this into the build OS environment.
- inst.ks and inst.repo: If you are used to ks= and repo= lines from earlier kickstart environments, you'll need to get used to these new parameters. You servers will not be able to find the repo or kickstart files without them.
- For each repo specification, I point to the files stored in the repo. There are a number of tutorials that have you copy the kernel (vmlinuz) and initial ram disk (initrd.img) files to a location such as /var/lib/tftpboot/images/, and pull from there. This is not a bad idea if you have limited space on the partition that holds /var. If you mount the repo under /var, however (or you have a large amount of disk space under /var, and can simply drop your repos there), I think it makes sense to reference the files inside the distribution rather than making a copy. This reduces duplication, and hence, complexity.
We'll get to more kickstart stuff later.
Configure the DHCP Service
Now we modify dhcpd so that it will hand out an address to a host attempting to PXE boot.
# vim /etc/dhcp/dhcpd.conf
Add the following & save:
allow booting;
allow bootp;
option option-128 code 128 = string;
option option-129 code 129 = text;
next-server 172.16.1.1;
filename "pxelinux.0";
These are the statements required to enable the DHCP service to support PXE. I have a subnet stanza in my configuration, and that stanza contains a 'class pxeclients' stanza. This came with the original dhcpd.conf file that I used. Since that stanza contains a set of options to determine the 'filename' line, I can omit that from the set of configuration options above.
The next-server tells the host that is obtaining an IP address where to look for a PXE boot environment. This is the address of our deploy server.
Save and quit:
:wq
The Kickstart Service
Red Hat and derivatives maintain a 'kickstart' service to help automate provisioning. In short, the kickstart configuration file is nothing more than a set of directives that anaconda (the installer) reads to determine how to install RHEL/CentOS/Scientific Linux on the host. Specifying the individual parameters in the kickstart file is well beyond the scope of this document, but will be critical for completing your deploy server. So, there are a few notes here on the topic.
Below in the References section is a link to the kickstart documentation published by Red Hat. The link below is specific to Red Hat (and thus CentOS) 7. Be wary, as there are a number of links out there pointing to many different versions, and it's usually only in the link that you can tell which document pertains to a specific version of the OS.
Creating a kickstart file from scratch is a very tedious task. Recognizing this, the good folks who maintain Anaconda provide a shortcut. To use this, do the following:
- Locate a suitable server that is as close to the specifications as what you will be using the deployment server for. You will be installing a new OS on this server, so make sure it isn't something you need.
- Using a CD, repo, or other source of the OS distribution files, install CentOS 7 on that server.
- Feel free to use the graphic installer; no need to make things difficult, and the graphic installer gives you more control over the disk layout.
- As you are installing, make the decisions/selections as if this would be a server you are deploying automatically from your deployment server. For example, if you are deploying an application server that does not require a GUI, don't select GUI, an so on.
- One final note: Going back to our build philosophy, consider configuring the server with only the 'core' files. That will be enough to boot the server, and we can then use the automated process later to add additional packages.
- Once the OS is installed, reboot the server, and log in as root (you must create the root account and password as part of the installation process).
- In root's home directory, locate the file anaconda-ks.cfg. This is your starter kickstart file. It contains all the directives necessary to deploy the OS you just installed.
- Make changes to the configuration file to allow unattended installation
- Locate the entry that describes the source repo (probably something like "cdrom"), and change to
- url --url="http://172.16.1.1/repository/CentOS-7-1511-x86_64"
- Locate the firstboot entry and change from --enable to --disable. Again, this will require that you manually configure network settings once the host is provisioned, but we'll deal with that later. Hint: once booted, login as root and type "setup".
- locate the line that reads "graphical" and change to "text".
- This should create a suitable kickstart file to start off with. There are many options to customize how kickstart works. I strongly encourage you to check out the link below, and learn more. Just remember, we want to do most OS configuration work after the OS installed.
- Add the 'reboot' directive at the end of the file to automatically reboot the server.
- Now, rename the file to something descriptive. From the PXE menu, you can see I have two, and named them CentOS7-1511-OVB_core.cfg and CentOS7-1511-KVM_base.cfg. This name is important. It's how we will distinguish one build type from another. It should contain enough information for you to tell which is the most suitable for a given server purpose. Mine describes the following:
- OS Name (CentOS): I may later want to provision Linux desktops with Linux Mint. This is how we tell the difference.
- OS Version (1511): While not as obvious, this tells us the version (7.2) and build (1511) of CentOS. Different builds will contain different packages, versions of packages, and configurations that determine how the server responds.
- Platform (OVB and KVM): Again, each kickstart file is slightly different depending upon the Virtual host software in use. In addition, there will be more differences when/if we start adding kickstart files for deploying to the server directly.
- Software set (core, base): Tells us which software set we installed. In my case, 'base' was a leftover from a previous installation, so I included it. If I had not had that already, I would likely have stuck to the design philosophy, and created a core installation to drop on KVM.
- Finally, create a directory to house your kickstart config files, set the permissions, and copy your new kickstart configuration file there:
# mkdir /var/lib/tftpboot/templates
# cp <your-kickstart.cfg> /var/lib/tftpboot/templates/
# chown -R apache.apache /var/lib/tftpboot/templates
# chmod -R 744 /var/lib/tftpboot/templates/*
# chmod -R 755 /var/lib/tftpboot/templates
Here is a sample kickstart file I created to test my unattended Oracle VirtualBox installations. One thing to note is that I've added an ansible account. We'll come back to that in a future posting. Also, you might note the '--device=' parameter was moved out of the first network line and into the second. This is not by accident. There is a bug in RHEL (and downstreams) that will cause an error if the 'device=' line is not in the same network directive line as '--hostname'.
#version=DEVEL
# System authorization information
auth --enableshadow --passalgo=sha512
# Use network installation
url --url="http://172.16.1.1/repository/CentOS-7-1511-x86_64"
# Use graphical install
text
# Run the Setup Agent on first boot
firstboot --disable
ignoredisk --only-use=sd
# Keyboard layouts
keyboard --vckeymap=us --xlayouts='us'
# System language
lang en_US.UTF-8
# Network information
network --bootproto=dhcp --ipv6=auto --activate
network --hostname=localhost.localdomain --device=eth0
# Root password
rootpw --iscrypted $6$Seed-text-string$This-string-will-be-replaced-with-the-encrypted-password.
# System timezone
timezone America/Chicago --isUtc
user --groups=wheel --name=ansible --password=$6$seed-text-string$Seed-text-string$This-string-will-be-replaced-with-the-encrypted-password. --iscrypted --uid=1001 --gecos="Ansible Admin Account" --gid=1001
# System bootloader configuration
bootloader --append=" crashkernel=auto" --location=mbr --boot-drive=sda
# Partition clearing information
clearpart --none --initlabe
# Disk partitioning information
part /boot --fstype="ext4" --
ondisk=sda --size=250 --label=BOOTPART
part swap --fstype="swap" --ondisk=sda --size=989
part / --fstype="ext4" --ondisk=sda --size=6750 --label=ROOTPART
%packages
@^minimal
@core
kexec-tools
%end
%addon com_redhat_kdump --enable --reserve-mb='auto'
%end
#Reboot the server upon successful installation
reboot
Configure firewalld and selinux
Shut off firewalld:
# systemctl stop firewalld.service
# systemctl disable firewalld.service
Disable selinux:
# vim /etc/sysconfig/selinux
Replace
SELINUX=enabled
with
SELINUX=disabled
Now save and exit:
:wq
Reboot
Now it's time to reboot. Again, this is really only necessary in the event that we changed the status of selinux. If it was already disabled you could simply restart each service as you configure it.
# reboot
Validate Services
Login as root, and run your validations on the services:
[root@deploy ~]# sestatus
SELinux status: disabled
[root@deploy ~]# for SERVICE in xinetd dhcpd httpd firewalld; do echo $SERVICE;systemctl status $SERVICE.service | grep Active;done
xinetd
Active: active (running) since Sat 2016-07-23 18:05:15 CDT; 16h ago
dhcpd
Active: active (running) since Sat 2016-07-23 18:05:36 CDT; 16h ago
httpd
Active: active (running) since Sat 2016-07-23 19:49:24 CDT; 15h ago
firewalld
Active: inactive (dead)
All services should show "Active: active (running) except firewalld, which we can inactive. (There are some tutorials on setting up firewalld to work with PXE booting, and it's not a bad idea at all from a security perspective. That said, it is very uncommon, even in very security-conscious organizations to place firewalls directly on the host. Generally, firewalling takes place in the networking layer, leaving hosts use those compute cycles for business processing.)
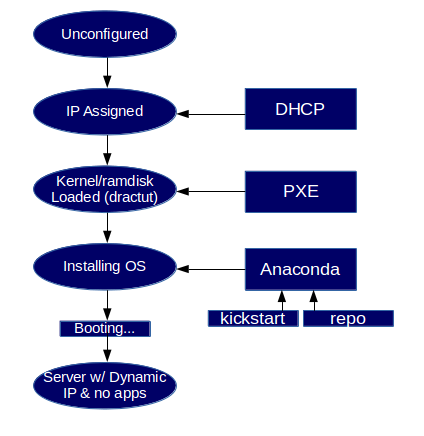
You can now create and PXE boot your new servers. Here is a small diagram demonstrating each state the new host is in from the moment of power-on to the end of the deployment process.
References